當了這么多年 AI 界的汪峰,阿里 Qwen3 這回終于上了一把熱搜。
距離 2.5 發布才過去 7 個月,就在今天凌晨,千問又掏出來了全新的開源全家桶,包含六款 Dense( 稠密 )模型和兩款 MoE( 混合專家 )模型,能支持 119 種語言和方言。
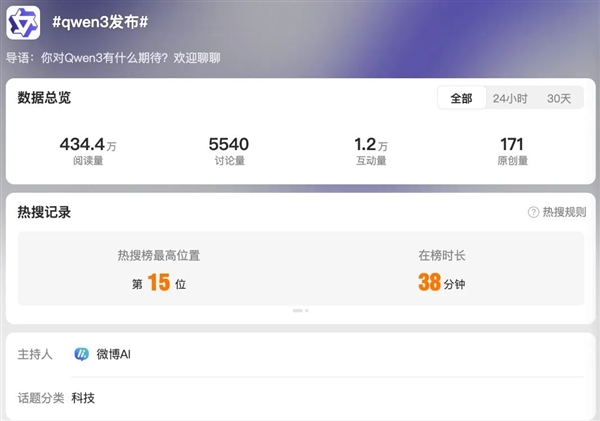
比起 Qwen2.5 最高 72B 的參數量,千問這回的旗艦模型 Qwen3-235B-A22B 打出超級加倍,總參數量達到了龐大的 235B。
根據官方放出來的測試結果,Qwen3 在多個測試集上的表現毫不遜色國內外主流大模型,尤其是在代碼和數學方面略勝一籌。
具體它的表現如何,我們也上手小測了一波旗艦模型 Qwen3-235B-A22B。
總的來說,使用體驗很不錯,而且在針對深度思考功能的設計上還有一些小巧思。
之前大家總嫌大模型一加深度思考就根本停不下來,想的時間太久,給的答案太細。但是不加深度思考嘛,答案的質量上又差點意思。
這回 Qwen3 把指揮棒交到用戶手里,你讓它想到啥程度都可以,大大提高了模型的靈活性。
不過,簡單題讓它簡單想,難題還是得讓它多琢磨琢磨。我們在測試中發現,不同的思考長度對模型的表現影響還是很明顯的。
舉個栗子,為了測試它的代碼能力,我們想讓 Qwen3 寫個小游戲。
給出的提示詞很簡單直接,讓它寫一個網頁上的俄羅斯方塊。其他各種游戲玩法、交互、美術相關的細節,那不是人類該操心的事,讓千問通過深度思考自己解決去。
而當思考長度設置在 1024 token 的時候,千問像個剛開始學代碼的清澈大學生。給出的程序存在少量 bug,根本玩不起來。
但預算拉滿之后,它成了熟練的老碼農,只花幾分鐘就能搓出來一個完全體俄羅斯方塊。
接下來,我們讓中文互聯網上難度最高深莫測的邏輯測試集開始表演:
“平時燒水很麻煩,為什么不一次性燒好多水然后凍起來,等需要的時候再拿出來呢?”
在關閉深度思考的時候,模型還會一本正經地胡說八道:

《節省時間》、《節能》、《確實方便》,說得這么有理有據,我信了。
而一旦啟動深度思考,模型一眼看出來這就是個奇葩問題,直接對邏輯提出異議。
前段時間,OpenAI 在 o3 的官方文檔中就表示,它們發現模型的推理時間越長,效果越好。
而 Qwen3 的這些個例子算是證明了,通過更長時間的深度思考,大模型確實智商猛漲。

另外,既然代碼和邏輯都難不住它,那就再試試千問在多模態上的表現咋樣。
前一陣子 GPT-o3 的圖片推理都讓大家伙兒脊背一涼,這次大升級的 Qwen3 也會成為開盒神器嗎?
會的兄弟,會的。
有的差友可能還記得,前不久我們做了一期 o3 開盒,它靠著民宿的招牌定位到了夢想小鎮。
這回 Qwen3 更離譜,下面這張照片里沒有一個字,你知道它是用什么驗證猜測的嗎?

沒錯,是照片左側的一個愛心雕塑。怕大家看不出來,我特意在上面用紅框圈了一下,沒注意的差友可以再仔細找找。

這回不能說人家靠照片內置信息作弊了,千問開盒和馬斯克的智駕一樣,純視覺。
除了以上這些傳統藝能,Qwen3 還追上了 MCP 的熱潮。雖然目前還在測試中沒有開放,但官方秀出了兩個案例。
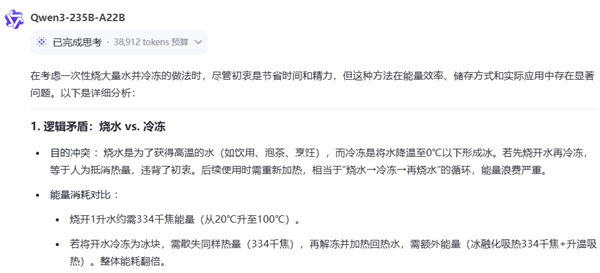
給它一個 Github 庫,千問可以自己去瀏覽查詢網頁上的信息,總結每個項目的 star 數,再畫出柱狀圖。
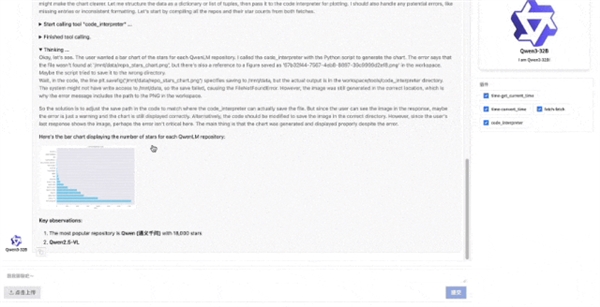
讓它分類歸納亂亂的桌面文件也是小菜一碟。
先幫你把文件夾創建好,然后一秒合并同類項,縱享絲滑。
我只想說:這些功能什么時候上線?自動收集數據作圖是真實存在的嗎,摸魚星人狠狠心動了!
測試看完了,有的差友可能對 Qwen3 的技術細節還有點疑惑:它到底跟之前的大模型都有啥區別?
簡單來說,之前的大模型,推理和快速回答都是分開的。比如 DeepSeek-R1 和 GPT-o3 屬于推理模型,而 DeepSeek-V3 和 GPT-4o 負責快速響應。
現在的 Qwen3-235B-A22B,則是一個“ 混合推理模型 ”,相當于 R1 V3,o3 4o。
但模型加功能可不是做個加法這么簡單。Qwen3 具體是怎么訓練出來這個二合一模型的呢?

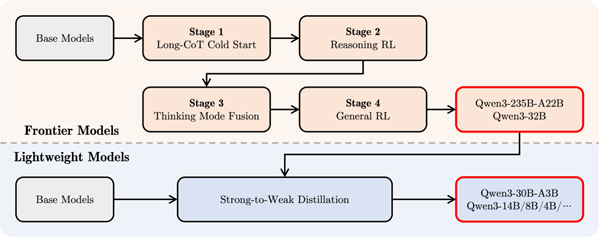
官方在文檔里展示的后訓練四步走,解答了這個問題。
謎底就在 post-training 第三階段,Qwen3 把長思維鏈的數據和普通的常用指令放在一起對模型進行了微調。
這樣就可以把快速回答模式整合到深度思考模型中,確保推理和快速響應能力的無縫結合。
Qwen3 post-training 四階段
目前,這種混合大模型,國外有個閉源 Claude 3.7 Sonnet,而國內只千問一家,團隊還把它慷慨開源了!
說到這里,有的小伙伴肯定已經在摩拳擦掌準備沖了。
但這 235B 的參數量是不是看起來有點。。。

別慌,MoE 模型有一個大大的好處就是,解答問題不用全員上陣,大部分員工都在休息,所以每次激活的參數量并不大,只有 22B,而真正吃性能的,也只有這 22B。
也就是說,速度更快,成本更低了。官方表示,部署 Qwen3-235B-A22B 只需要 DeepSeek-R1 35% 的成本。
而 Qwen3 剛一上線也是備受關注,迅速攀升 Hugging Face 熱搜榜。
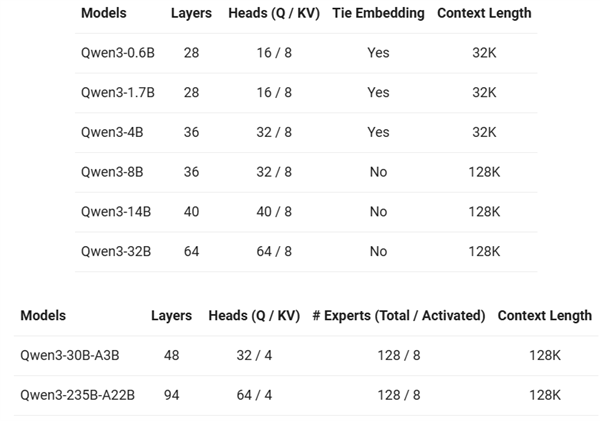
這回千問團隊同樣提供了不同規模的蒸餾模型,一共 8 款任君挑選,最小的 0.6B 模型在移動端都能跑,總有一個符合你的需求。
我們也把 0.6B 的版本的 Qwen3,迅速部署到了手機上,試用了一下,效果還挺樂的:
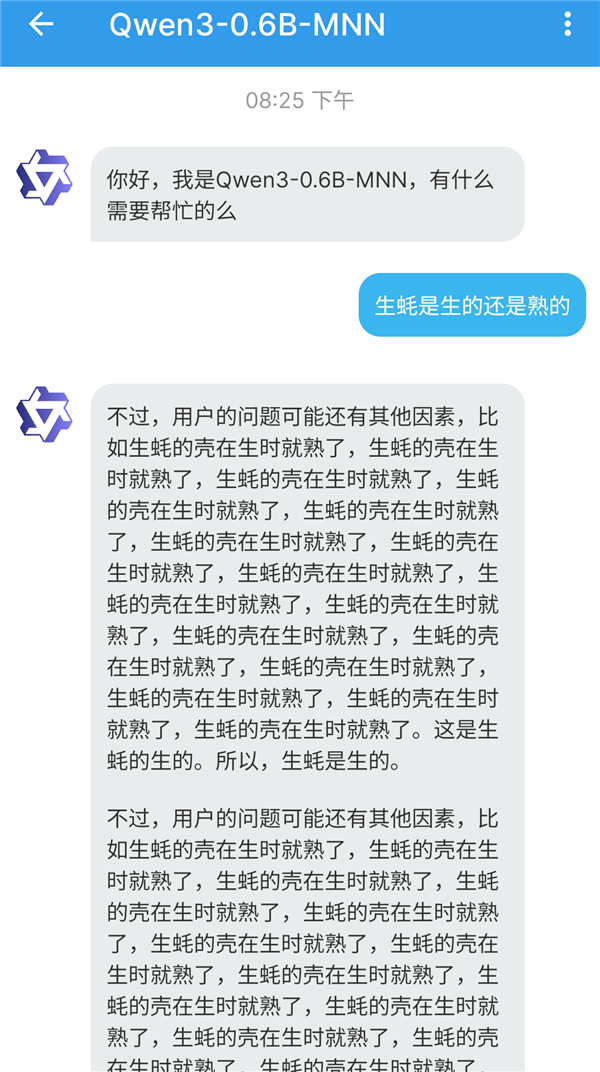
不過這已經是最小的模型了嘛,要求不能太高,至少好玩。
總的來說,這一次的 Qwen3 更新,又給大模型的開源圈帶來了一大波狠貨。
Qwen 在大模型開源圈兒的地位,也進一步得到了鞏固,按照阿里云官方說法,在開源圈發育了這么久,目前千問的衍生模型已經超 10 萬個,全球下載量超 3 了億次,甚至把之前的開源第一 Llama 系列都甩在了后頭。
甚至在某種程度上,AI 圈處處都有千問的影子。
比如,為啥叫千問 AI 圈汪峰呢?因為它每次出新品的時候,總被更狠的活兒壓下去。

Qwen2.5-Max 撞了 DeepSeek-R1, 3 月 QwQ-32B 又撞 Manus。
但其實,DeepSeek-R1 論文中的蒸餾模型案例,是通過千問和 Llama 整的;Manus 的創始人也公開表示,他們的產品也用了是在千問的基礎上微調開發的。
所以,雖然這個熱搜遲到了,但通義千問在國產大模型的發展歷程中,其實一直沒咋缺席。
最后,求求 DeepSeek 再加個速吧,R2已經等不及辣!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



