部署超大規模MoE這件事,國產芯片的推理性能,已經再創新高了——
不僅是“英偉達含量為0”這么簡單,更是性能全面超越英偉達Hopper架構!

而做到這一點的,正是華為昇騰;具體而言,共包含兩個產品:
CloudMatrix 384超節點部署DeepSeek V3/R1,在50ms時延約束下單卡Decode吞吐突破1920 Tokens/s
Atlas 800I A2推理服務器部署DeepSeek V3/R1,在100ms時延約束下單卡吞吐達到808 Tokens/s,可支持靈活的分布式部署
之所以能夠這般,是因為華為昇騰所采取的“以數學補物理”——這種通過數學理論、工具、算法和建模等方式,來彌補硬件和工藝的局限性,實現最大化發揮芯片和系統能力效果。
華為昇騰還不只是“官宣”一下而已,后面更會是全面開源。
不僅已經將昇騰在超大規模MoE模型推理部署的技術報告分享了出來,在一個月時間內,還會把實現這些核心技術的相關代碼也都會陸續開源出來。
那么接下來,我們就來深入了解一下華為昇騰背后的技術實力。
在華為昇騰上推理DeepSeek
在深挖華為昇騰背后技術創新之前,我們且需了解一下為什么要這么做。
從2017年Google提出的Transformer架構,到2025年DeepSeek V3/R1的爆紅,大語言模型的重心正在從訓練開發轉向推理應用落地。
推理能力不僅是大模型能力的“試金石”,各大企業已從 “拼模型參數” 轉向 “拼推理效率”:
誰能讓大模型在實際應用中跑得更快、更穩、更省資源,誰就能在商業化浪潮中搶占先機。
然而,以6710億參數的DeepSeek V3為例,這類超大規模MoE模型雖然強大,卻給硬件帶來三大 “成長煩惱”:
內存壓力山大一個模型包含257個專家,每個專家 “體重” 2.5G,普通64GB內存的AI硬件根本 “扛不動”,必須依賴集群協作。通信開銷爆炸專家分布在不同芯片上,數據傳輸耗時甚至超過計算時間,就像團隊成員頻繁開會溝通,效率大打折扣。架構創新的 “甜蜜負擔”例如 “多頭隱式注意力機制(MLA)” 雖然壓縮了數據空間,卻導致中間變量激增,對芯片的計算能力提出更高要求。
面對這些挑戰,華為團隊從算子、模型和框架三方面入手,基于昇騰硬件特性,開發了一整套面向集群的大規模專家并行解決方案。
在硬件部署上,華為團隊根據不同硬件配置——CloudMatrix 384超節點和Atlas 800I A2推理服務器,針對性地采取了不同的部署優化策略。為解耦Prefill和Decode階段的時延約束,昇騰采用PD分離部署方式。
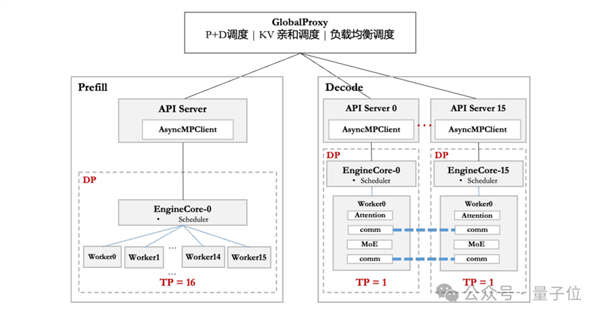
在框架側,昇騰基于vLLM框架,適配DP和EP等多種并行策略,通過Prefill調度分桶、靈衢互聯與分層傳輸等技術來降低調度開銷,優化請求下發、調度策略等環節,提升系統性能。
在模型方面,昇騰采用A8W8C16量化策略,其中A8W8使用INT8,C16使用BF16,并針對不同機型進行差異化部署。
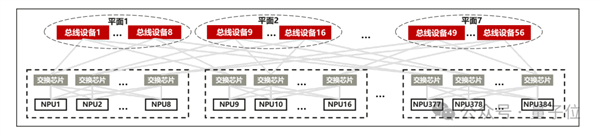
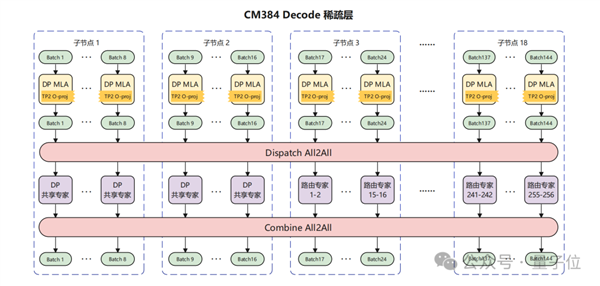
針對CloudMatrix 384超節點,其強大的組網能力大幅降低了通信耗時,釋放了昇騰芯片的算力。
團隊采用大規模EP并行部署,Prefill使用16卡,Decode使用144卡,其中128卡部署路由專家,16卡部署共享專家,MLA部分采用DP部署。
盡管存在時延約束、帶寬搶占、調度開銷、負載不均等因素影響,最終在50ms時延下,單卡decode吞吐達到1920 Token/s。
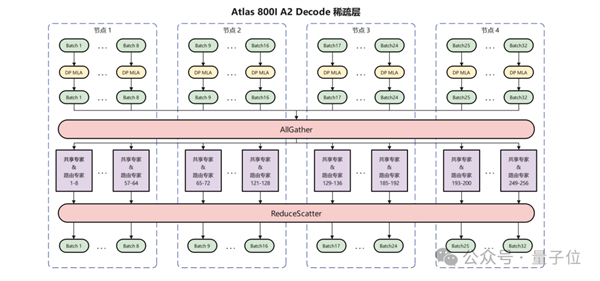
針對機群規模較小但部署更加靈活的Atlas 800I A2服務器,華為團隊采用多節點互聯的方式進行部署。
作為示例,華為團隊使用2機16卡進行Prefill,4機32卡進行Decode,每卡部署8個路由專家和1個共享專家,MLA部分采用DP并行,并針對性地使用在真實負載下性能更優的AllGather/ReduceScatter的通信方案。
通過各種策略優化,在100ms時延下,單卡吞吐達到808 Tokens/s。
還有更多優化技術
在推理框架優化方面,針對高并發場景下單點API Server這一性能瓶頸,華為團隊設計了API Server橫向擴展方案,采用水平擴展技術提升框架的請求響應能力,顯著降低用戶請求延遲并提高整體服務吞吐量(QPS)。
針對MoE模型中的負載不均問題,基于動態調整專家部署與縮小通信域、熱專家冗余部署、實時調度與動態監控機制等核心技術,降低顯存占用的同時實現動態負載均衡。
在投機推理技術的工程化應用中,如何將其從小批量低時延場景擴展至高吞吐量場景,是行業面臨的共性難題。
華為團隊基于昇騰芯片高計算帶寬比的硬件特性,提出FusionSpec投機推理引擎,針對性優化多Token預測(MTP)場景下的推理性能:
流程重構將投機模型后置於主體模型,直接復用主體模型的輸出結果與控制參數,大幅減少框架耗時,完美適配參數-數據分離(PD 分離)的分布式部署架構;輕量步間優化對投機推理場景中的框架和算子優化實現了輕量步間準備,適配多核并行的全異步框架。
在通信優化方面,華為昇騰也有三大妙招。
首先,針對主流張量并行(TP)方案中AllReduce通信的固有缺陷(通信次數多、數據量大、冗余計算顯著),華為團隊推出FlashComm通信方案,通過集合通信邏輯重構與算子位置編排,實現低比特、低維度數據通信,在降低通信時延的同時消除冗余計算,最終實現25%通信量的降低和10%推理性能的提升。
其次,在FlashComm基礎上,團隊進一步提出層內并行轉換方案,針對Prefill階段的MLA層,通過張量并行(TP)與數據并行(DP)的靈活轉換,消除節點內卡間求和操作,并利用網絡低維特性與量化技術壓縮通信數據量,顯著降低跨卡通信時延,為大模型分布式推理提供更高效的通信支撐。
第三,通信方面的優化還有一個并發機制的深度挖掘,包括:
計算通信并發通過Gate函數計算與AllGather通信的解耦,結合共享專家的數據并行(DP)策略,利用昇騰多流機制實現計算與通信的并發執行,最大化硬件利用率;通信通信并發針對DeepSeek模型的量化場景,將激活值與scale的傳輸任務并行處理,在不增加帶寬壓力的前提下掩蓋小數據量通信的啟動開銷;通信和權重預并發利用通信階段HBM帶寬低占用特性,提前將后續算子權重預取至緩存,降低計算階段的數據搬運開銷,實測MLA層計算性能提升10%。
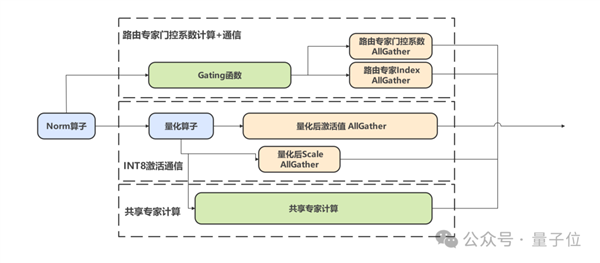
最后,就是在算子方面的優化了。華為團隊通過以數學補物理,發展了一系列的優化技術。
針對MLA算子中間變量膨脹與計算量激增的挑戰,團隊開展硬件親和性優化:
算法重構:提出AMLA算法,通過二進制編碼與存內計算,將乘性計算轉換為加性等價形式,直接在全局內存完成輸出更新,減少數據搬運耗時;緩存策略:通過L1/L2緩存精細化管理與K-buffer流水排布,提升緩存命中率與計算效率,實現張量計算與向量計算的相互掩蓋;前序算子融合:在Prefill與Decode階段分別采用雙流并發與算子融合技術,結合權重預取、分塊策略及定制指令集優化,構建端到端高效計算鏈路。
MoE算子方面的優化則包括:
通算融合算子:針對EP部署模式下MoE專家的跨卡調度難題,設計MoeDistributeDispatch/Combine算子,通過 Token 粒度的流水排布與內存語義通信技術,將通信與計算并行化,減少卡間同步開銷;SMTurbo-CPP技術:針對小數據量通信效率問題,通過讀寫混合、聚合流水等硬件并發技術,提升AllToAll(v)算子的吞吐能力,降低Dispatch/Combine場景時延;細粒度分級流水算法:基于Atlas 800I A2組網特性,實現節點內/節點間的集合通信并發執行,大幅提升集群環境下的帶寬利用率。
性能創新高
在Decode性能測試方面,Atlas 800I A2所采用的方式是:
序列長度為2K輸入 2K輸出和1K輸入 2K輸出兩種情況在使能MTP進行推理加速的情況下,由于不同測試數據集和業務場景的MTP接受率不同,性能測試結果會有比較大的偏差。因此在計算時延和吞吐的時候默認按照70%接受率來折算。TPOT(Decode平均每Token時延)不超過100ms。
具體表現如下所示:
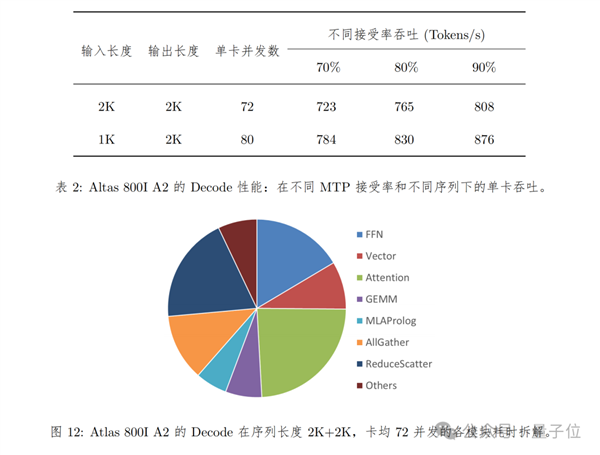
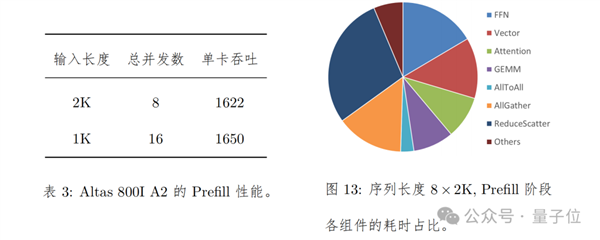
在Prefill上的測試方法是,單batch輸入序列長度為2K/1K,通過拼batch的方式拼成一共16K序列。對于序列長度是2K,共8 batch拼成一共16K序列的場景,端到端耗時為631ms,卡均吞吐為1622 Tokens/s。
具體表現如下圖所示:
在2025年4月,硅基流動聯合華為云基于CloudMatrix 384超節點昇騰云服務和高性能推理框架SiliconLLM,用大規模專家并行最佳實踐正式上線DeepSeek-R1。
該服務在保證單用戶20 TPS(等效50ms時延約束) 水平前提下,單卡Decode吞吐突破1920 Tokens/s,可比肩H100部署性能。

而也正如我們剛才提到的,昇騰在超大規模MoE模型推理部署的技術報告分享了出來了,想要更深入了解的小伙伴,可以在文末鏈接中自取哦(或點擊文末【閱讀原文】)~
One More Thing
就在本周,華為昇騰還將舉辦一個技術披露周!
大家可以關注https://gitcode.com/ascend-tribe/ascend-inference-cluster/中每天的上新。
具體詳情放下面嘍,小伙伴們可以蹲一波了~

完整技術報告:點擊獲取
技術博客:點擊跳轉
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



