看到今年的畢業(yè)季,估計王勃會氣得從地里爬出來,把開發(fā)AIGC檢測模型的人電腦插頭拔了。
事情是這樣的:
今年很多學(xué)校為了防止學(xué)生用AI寫畢業(yè)論文,在論文送審時加了一項“AIGC檢測”,意思就是檢測你文章里多少內(nèi)容是由AI生成的。

起初,這條公告并沒有掀起什么波瀾。
但直到最近,大伙的論文都接近尾聲了,才發(fā)現(xiàn)這玩意兒讓大伙的畢業(yè)季變成了走馬燈。
“我寫的內(nèi)容會被識別成AI,而AI寫的反而不會被識別成AI,因此AI檢測論文就是在檢測誰能把話說的更不像人話。”25屆畢業(yè)生小蛋如是說,此處內(nèi)含臟話過濾器。
大伙發(fā)在網(wǎng)上的評論,更是一個比一個離譜。
因為自己寫得太專業(yè),被檢測成AI寫的。
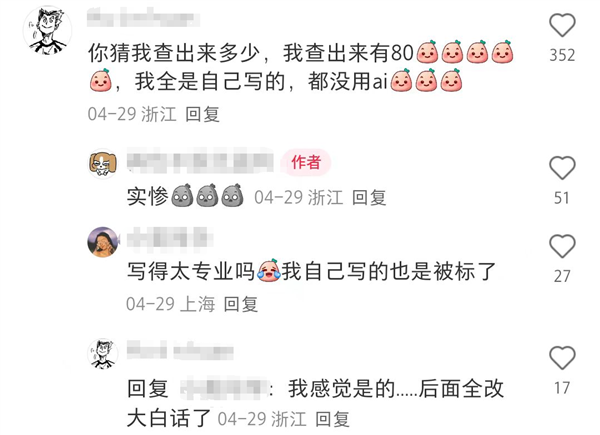
有給導(dǎo)師改一遍,AI生成疑似度反而漲了的。
甚至有人把《滕王閣序》塞進(jìn)去,發(fā)現(xiàn)其AI生成疑似度高達(dá)驚人的99.2%。

這下合理了,原來咱勃哥開的是AI掛,我就知道沒人能即興寫出這么好的文章。
我估計是因為,這文章寫得太華麗了,對仗工整,用典密集,信息密度巨大,跟現(xiàn)在的AI文章確實是有點相似之處的。
而且,你猜怎么著?AI生成疑似度的檢測,也是由AI進(jìn)行的。
這活兒,別說碳基生物了,硅基生物都想不到,自己被設(shè)計出來,要幫人寫文章,改文章,還要幫你猜猜這文章是不是人寫的??早知道上輩子爛在服務(wù)器里了。
為了和廣大畢業(yè)生感同身受,咱也掏出了同事珍藏已久的畢業(yè)論文,用了大伙的同款工具來試試水。
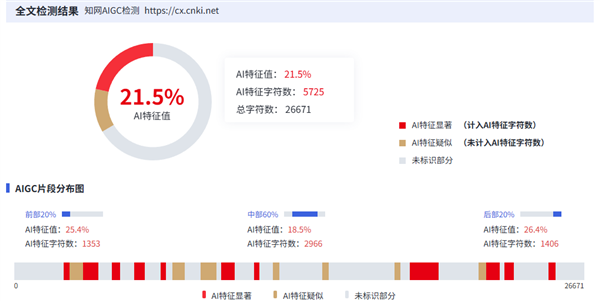
從結(jié)果來看還可以,能勉強(qiáng)能達(dá)到畢業(yè)要求,看來論文含金(shi)量還是有的。
但從過程來看,就有點搞笑了。

比如,這段就是單純的名詞解釋,你讓人來寫和AI來寫都是這么個解釋,客觀規(guī)律不以人類意志為轉(zhuǎn)移。
但它覺得是AI生成的,意思是我還得加點修辭手法嗎?

而這段呢,是我對前人工作的總結(jié),看過論文的人都知道,包不可能一個字一個字看的呀。這個部分其實是我把文獻(xiàn)丟給AI讓AI總結(jié),最后一句一句拼起來的。然而,它并沒有檢測出來。
所以說,要是同事畢業(yè)那年有這指標(biāo),還真得開罵,這結(jié)果根本就不準(zhǔn)啊。
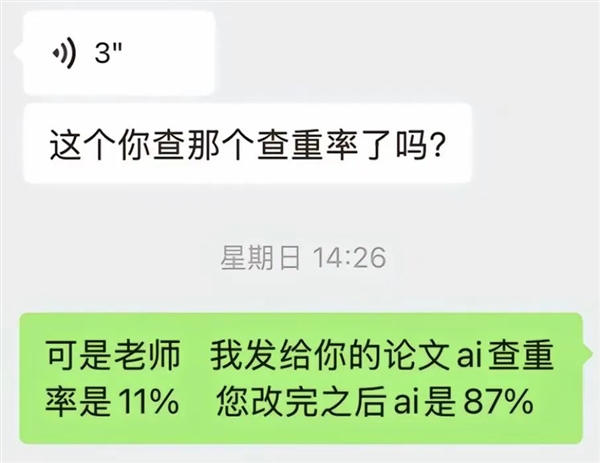
更何況一共四萬多字,就要了我84塊。如果有人AI生成疑似度死活降不下去的話,我能感受到一種砸鍋賣鐵的絕望。

而且,這股潮流不光在國內(nèi)涌動。身處英國的老樹同學(xué)表示:“基本上所有小組作業(yè)都要檢測一遍,而且相當(dāng)不準(zhǔn)。身邊同學(xué)都挺煩這玩意的。”
可以說全世界都籠罩在AI的烏云之下。
而之前,咱也就試了一下論文這種專業(yè)性強(qiáng)的東西,我就很好奇啊,它是不是啥也不準(zhǔn)。于是我當(dāng)場手碼了一段文字,讓AI給我檢測下。
看這無敵的邏輯性,就知道AI肯定寫不出來。
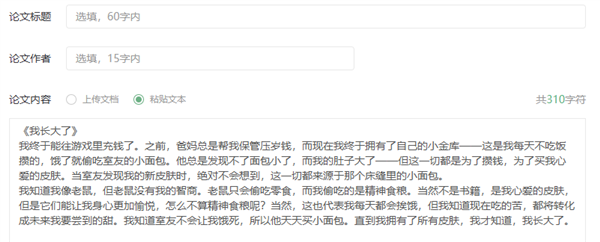
然后提交上去。

于是,我的努力和汗水化為了一串冰冷的97.77%。
所以,檢測AI生成疑似度的原理到底是啥?不能AI說啥就是啥吧?
沒想到吧,還真是。
當(dāng)你把文字輸入檢測工具時,它會分析這段文字的各種語言特征,包括詞匯、句子結(jié)構(gòu)、段落銜接方式等等。
然后,它會將這些特征與AI的寫作模式進(jìn)行對比。
對比分析后,檢測工具就會得出一個判斷,并不是絕對地告訴你“是”或“不是”,而是一個基于語言特征的概率推斷。

但這種玩意其實就沒準(zhǔn)過。
像OpenAI在ChatGPT剛發(fā)布時,就推出了自己的AI文本識別工具AI Text Classifier。
但準(zhǔn)確性就很拉了,只有約26%,還把莎士比亞的作品當(dāng)成AI生成的。
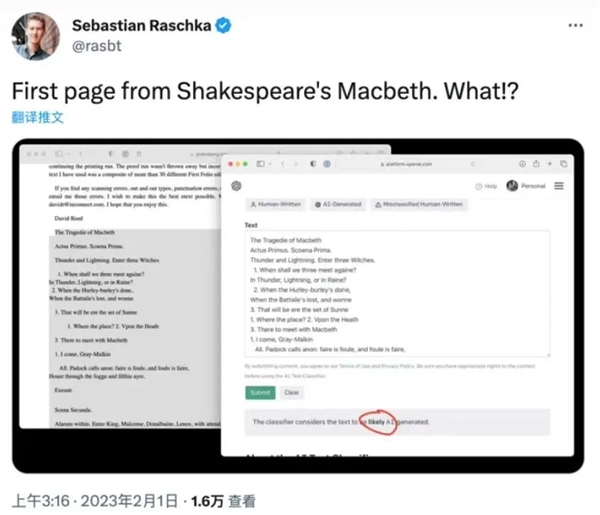
這種文本分類器的原理也很簡單,本質(zhì)上就是一個經(jīng)過特殊訓(xùn)練的模型,用來捕捉AI與人類文本之間的差異。
當(dāng)AI寫出的文本越來越像人類,分類器也越來越難跟上這種變化,導(dǎo)致它的判斷完全不準(zhǔn)確,甚至比瞎蒙還不準(zhǔn)確。
就算它看出來了,你隨便加一點,它也就看不出來了。
再說了,刨去準(zhǔn)不準(zhǔn)的事兒不提,AI本身就是用來模仿人的寫作風(fēng)格的。把人類的文章拿來訓(xùn)練AI,再把AI拿來檢驗人類寫出的文章像不像AI,本身就有一種“爸爸像兒子”般的荒謬。
意思是AI學(xué)會了我的寫作風(fēng)格,我就再也不能用這種風(fēng)格了嗎?那留給人類的時間不多了。
而且,擁有不確定性,就意味著一定會導(dǎo)致誤傷。
拿這個作為畢業(yè)指標(biāo),是不是有點拼運(yùn)氣了?這一整,沒有大保底,非酋怕是畢不了業(yè)了,肄業(yè)原因是臉太黑。
于是,大家只能費盡心思,把自己的文章改得越來越不像人。
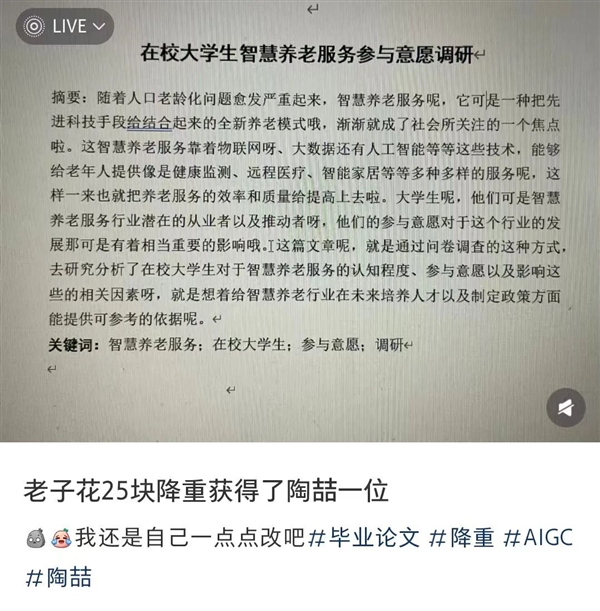
但,查完這個AI生成疑似率,才算邁過了第一道坎兒。
寫過論文的朋友們都知道,很多大學(xué)都有自己的檢測系統(tǒng),卻不喜歡給學(xué)生試用,為了順利畢業(yè),學(xué)生只能自掏腰包去第三方網(wǎng)站自查。
查重降重這種東西本來就要花錢。而現(xiàn)在又多了一項指標(biāo),就意味著要花錢的地方又多了一頭。
但有個非常奇特的現(xiàn)象,用不同網(wǎng)站測同一篇文章,AI生成疑似度完全不一樣,甚至相同網(wǎng)站不同時間的結(jié)果也不一樣。
這導(dǎo)致學(xué)生被迫成了無頭蒼蠅——誰主張誰舉證,這些網(wǎng)站都在主張你疑似使用AI,但根本沒有證據(jù),甚至沒有一個統(tǒng)一的標(biāo)準(zhǔn)。所以,到底要怎么改呢?
這時,你再點進(jìn)這些網(wǎng)站,就會發(fā)現(xiàn)從AI寫作,AI查重,AI降重,AIGC檢測,到降A(chǔ)I生成疑似度,所有需求,一站滿足,哪里不會點哪里,結(jié)果嘛就是都要掏錢。
甚至有的網(wǎng)站還會故意拉高這些數(shù)字,目的嘛,也就可想而知了。
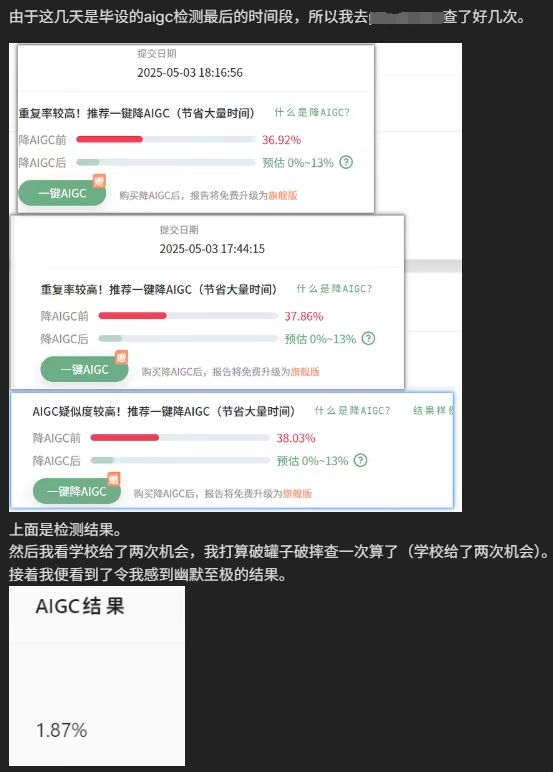
所以,畢業(yè)論文,真有必要檢測AI生成疑似度嗎?我們來看看教育部對畢業(yè)設(shè)計的要求:

可以看出,本質(zhì)上,就是檢驗?zāi)愦髮W(xué)四年有沒有學(xué)到真東西,擁有發(fā)現(xiàn)問題、解決問題的能力。
所以,理論上只要把活老老實實干完,保證實驗嚴(yán)謹(jǐn),數(shù)據(jù)真實,就達(dá)到要求了。
用AI把我的工作,用學(xué)術(shù)風(fēng)格寫出來又怎么了?
AI的發(fā)明就是用來減輕人類負(fù)擔(dān)的,它們早已成為很多研究者工作中的一部分。
中科院理化研究所的楊曉濤博士就曾表示過,單位和導(dǎo)師都鼓勵科學(xué)家學(xué)習(xí)使用AI工具,也會讓他們思考如何與科研結(jié)合。
而高校卻不允許我們的學(xué)生使用AI,又怎么能接近真正的研究者呢。
當(dāng)然,或許真的有這種學(xué)生,基本全篇都用AI生成,確實是在蒙混過關(guān)。
但,這其實也很好解決。AI用多了,你就會發(fā)現(xiàn),肉眼辨AI基本上就夠用了。
太離譜的文章,一眼能看出來是AI一作的,肯定是過不了關(guān)的。但一眼看不出來的,說明和人寫的已經(jīng)所差無幾了——只要內(nèi)容詳實,又何必在意詞句?
與其糾結(jié)AI生成疑似度,不如把目光放到內(nèi)容真實性上來,一篇論文中包含的努力和汗水,才是其中最寶貴的東西。
總之,AI被發(fā)明的初衷是服務(wù)人類,現(xiàn)在讓大家和AI斗智斗勇,屬實是有點沒事找事了。
處在AIGC元年的大伙,在此刻也終于理解了王勃——時運(yùn)不齊,命途多舛;三尺微命,一介書生。
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。



